Unidad 4.1
dgonzalez

Propiedad de los estimadores
Para una variable con distribución uniforme \(unif(a=0, b=20)\) se desea determinar las propiedades de los siguientes estimadores del parámetro \(b\)
\(\widehat{\theta_{1}} = 2 \bar{x}\)
\(\widehat{\theta_{2}} = \max\{x\}\)
\(\widehat{\theta_{3}} = \dfrac{(n+1)}{n} \max\{x\}\)
# uniforme
library(ggplot2)
x= c(0,20)
fx=c(1/20, 1/20)
dat=data.frame(x,fx)
ggplot(data=dat,aes(x=x, y=fx))+
scale_y_continuous(limits=c(0,.05))+
geom_line(size = 1,colour = 'red') 
Para ello se realiza una simulación, para posteriormente evaluar los estimadores propuestos y determinar sus propiedades.
library(ggplot2)
n=10
m=1000*n
Y=matrix(runif(m, min=0, max=20), ncol=n) # matriz de datos m x n
Mx=apply(Y,1,mean)
Max=apply(Y,1,max)
T1=2*Mx
T2=Max
T3=((n+1)/n)*T2
T123=data.frame(T1,T2,T3)
boxplot(T123, las=1, main="Comparación estimadores con n=10")
abline(h=20, col="red")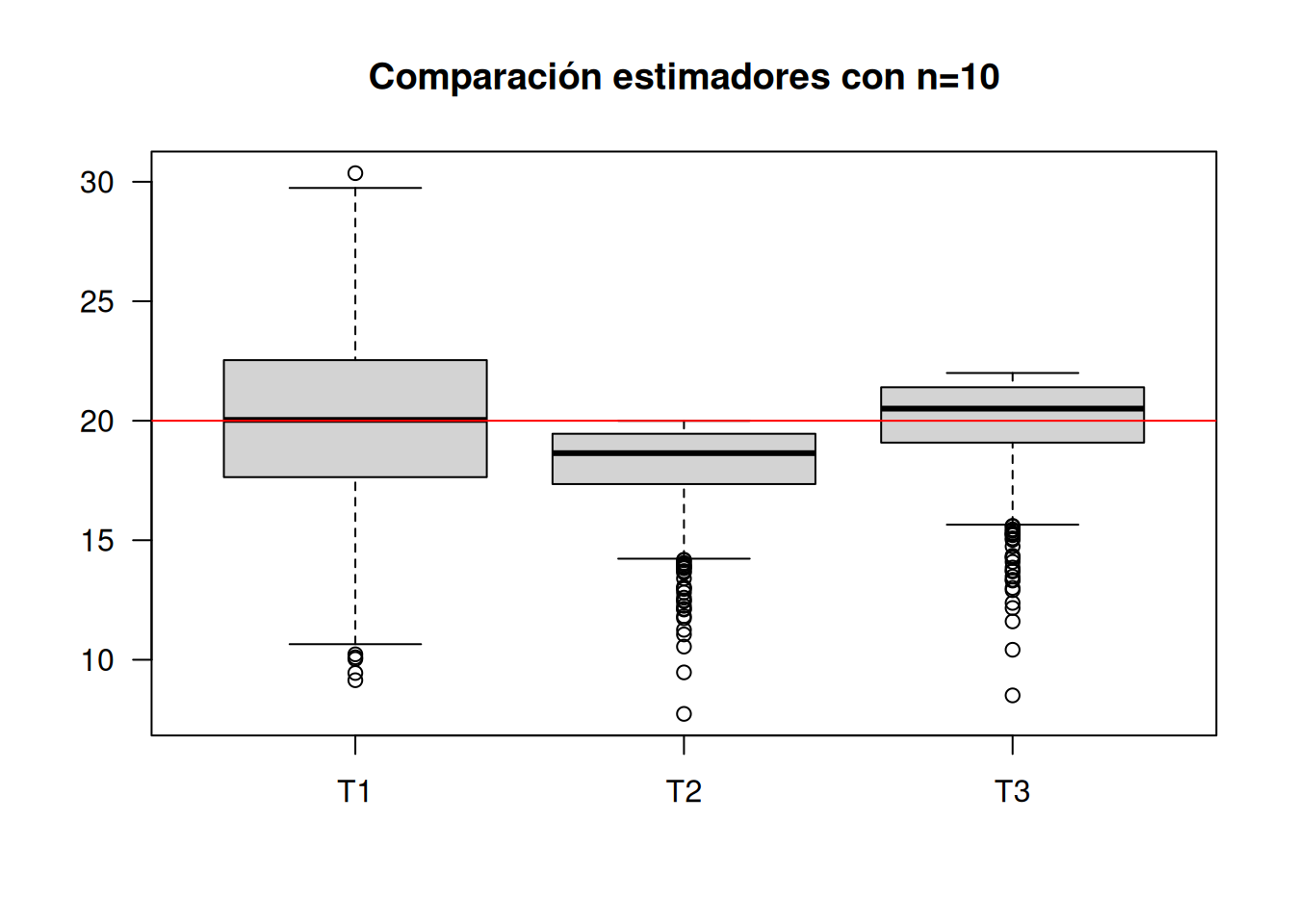
apply(T123,2,mean) T1 T2 T3
20.01804 18.18902 20.00792 Para un tamaño de muestra n=10 se observa que los mejores resultados se obtienen con T3. Este estimador se puede clasificar como INSESGADO y EFICIENTE, pues ademas que su promedio está muy cerca de 20, tiene la menor varianza
n=100
m=1000*n
Y=matrix(runif(m, min=0, max=20), ncol=n) # matriz de datos m x n
Mx=apply(Y,1,mean)
Max=apply(Y,1,max)
T1=2*Mx
T2=Max
T3=((n+1)/n)*T2
T123=data.frame(T1,T2,T3)
boxplot(T123, las=1, main="Comparación estimadores con n=100")
abline(h=20, col="red")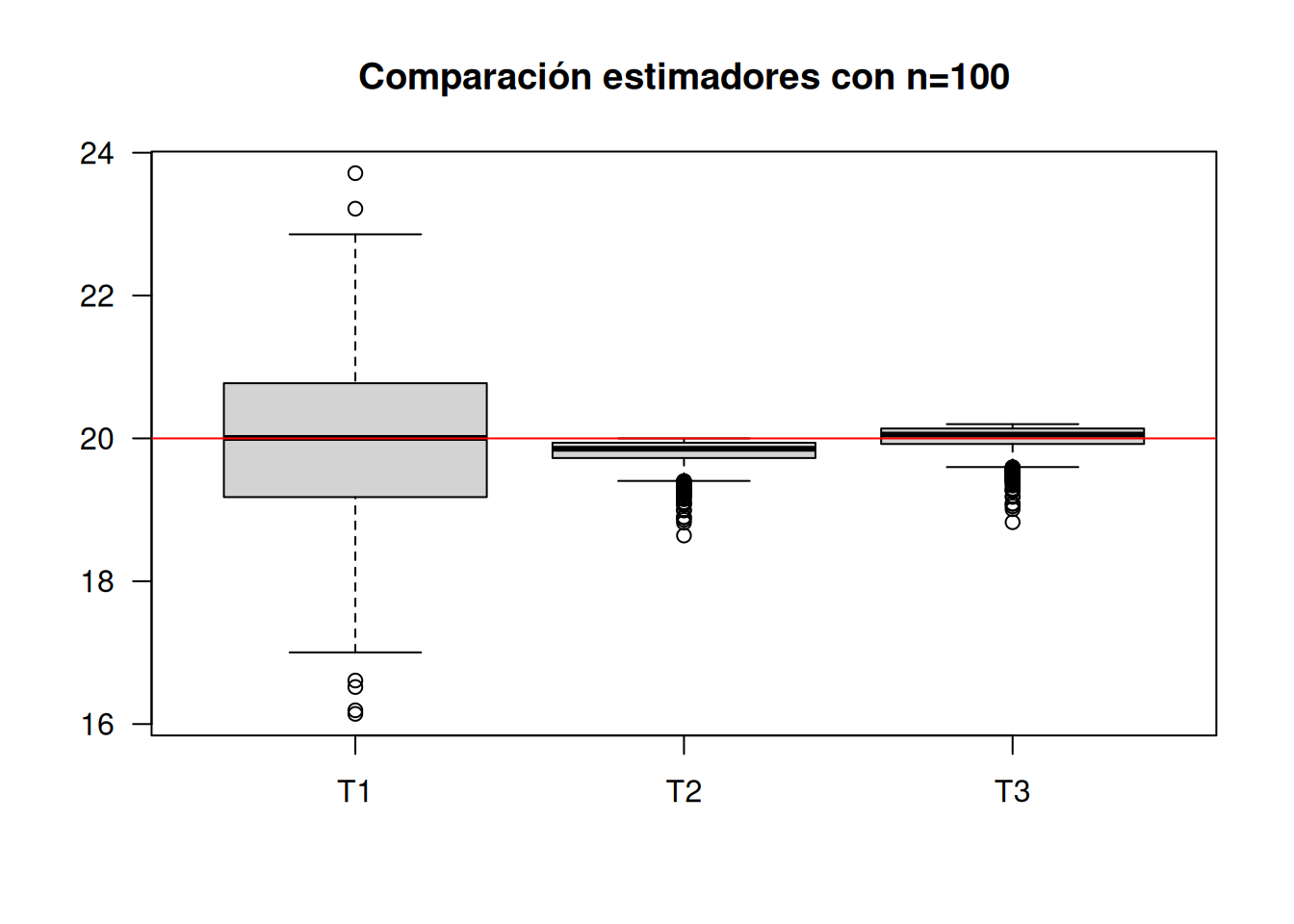
apply(T123,2,mean) T1 T2 T3
19.95247 19.79988 19.99787 Los resutados indican que el mejor estimador de b corresponde a T3. Sin embargo el estimador T2 que era insesgado al aumentar el tamaño de la muestra pasando de n=10 a n=100 se observa que su promedio se acerca mas a 20 que corresponde al valor del parametro
Teorema Central del Límite
Verificación del Teorema Central del Límite para una población exponencial con \(\lambda=1\)
Con este fin se siguen los siguientes pasos:
- Se construye una matriz de dimensión 1000 x 1000 con números procedentes del modelo determinado
- Se separan matrices de dimensión 1000 x n , para n=1,2,20,30,50, 100 y 1000 .
- A cada matriz construida en el paso anterior se le calcula la media por filas, como resultado se obtiene un vector de 1000 medias
- Cada uno de los vectores resultantes se visualiza a través de un histograma, gráfico de densidad y se construye también un gráfico de normalidad con el fin de validar el resultado
par(cex=0.5, cex.axis=.5, cex.lab=.5, cex.main=.5, cex.sub=.5, mfrow=c(3,2), mai = c(.5, .5, .5, .5))
# Teorema Central del Límite-----------------------------
# Paso 1
n=1000 # numero de columnas (tamaño máximo de muestra)
m=1000*n
# Caso --------------------------------------------------
# distribución exponencial-------------------------------
X=matrix(rexp(m,1),ncol=n)
# Paso 2
# generación de muestras-------------
X1=X[ ,1] # n=1
X2=X[ ,1:2] # n=2
X20=X[ ,1:20] # n=20
X30=X[ ,1:30] # n=30
X50=X[ ,1:50] # n=50
X100=X[ ,1:100] # n=100
X1000=X[ ,1:1000] # n=1000
# Paso 3
# generacion de medias---------------
Mx2=apply(X2,1,mean) # medias de muestras de tamaño n=2
Mx20=apply(X20,1,mean) # medias de muestras de tamaño n=20
Mx30=apply(X30,1,mean) # medias de muestras de tamaño n=30
Mx50=apply(X50,1,mean) # medias de muestras de tamaño n=50
Mx100=apply(X100,1,mean) # medias de muestras de tamaño n=100
Mx1000=apply(X1000,1,mean) # medias de muestras de tamaño n=1000
# Paso 4
# generación de densidad empírica --
d=density(X1)
d2=density(Mx2)
#d20=density(Mx20)
d30=density(Mx30)
d50=density(Mx50)
d100=density(Mx100)
d1000=density(Mx1000)
# Gráficos de densidad -------------------------------
# configuración de las gráficas
par(cex=0.5, cex.axis=.5, cex.lab=.5, cex.main=.5, cex.sub=.5, mfrow=c(2,2), mai = c(.5, .5, .5, .5))
# histogramas de comparacion-------------------------
plot(d, main=" ", xlab = "n=1")
plot(d2,main=" ", xlab = "n=2")
#plot(d20, main="", xlab = "n=20")
plot(d30, main=" ", xlab = "n=30")
plot(d50, main=" ", xlab = "n=50")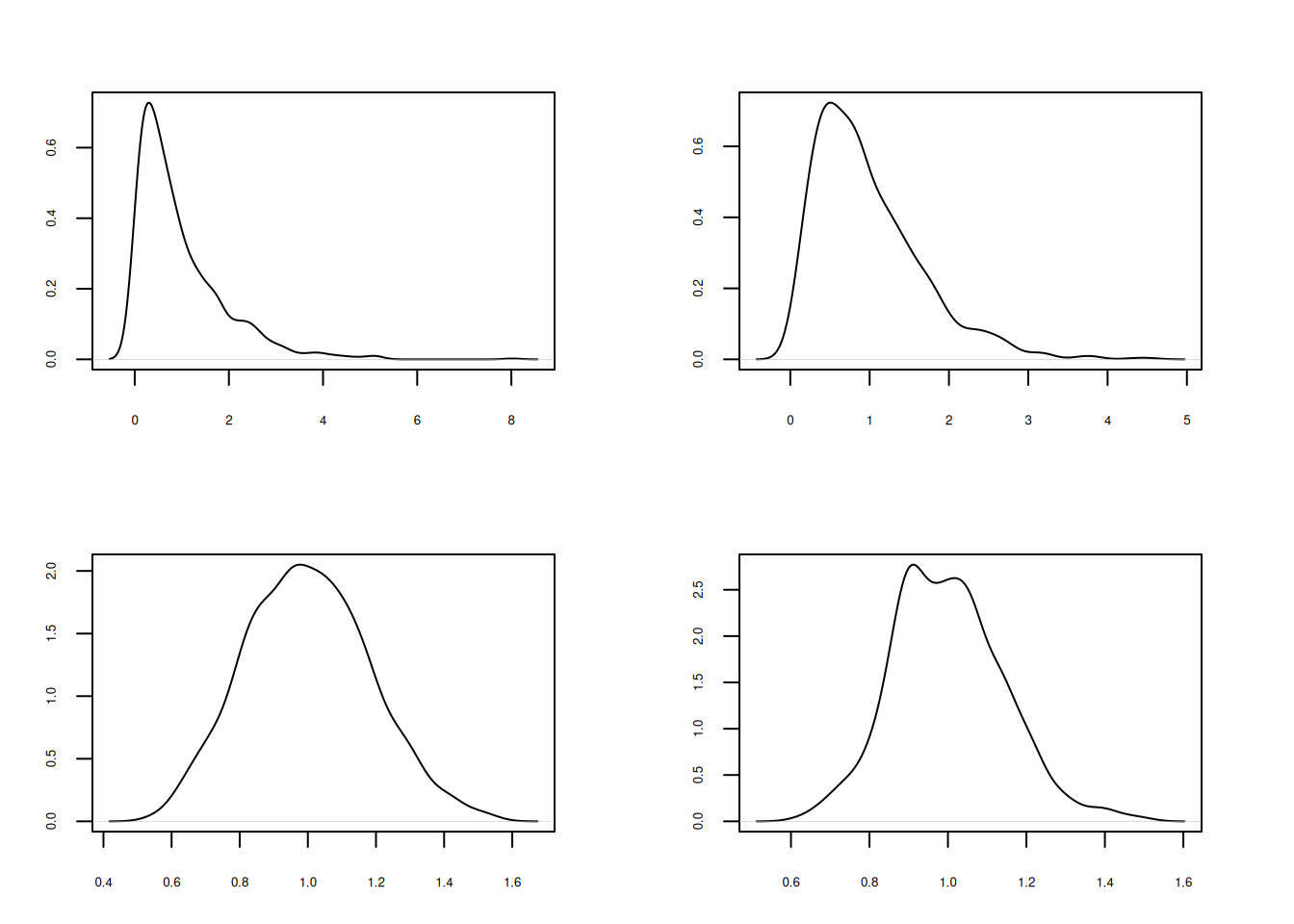
plot(d100, main=" ", xlab = "n=100")
plot(d1000,main=" ", xlab="n=1000")
# histogramas de comparacion--------------------------
hist(X1, main = "n=1", freq=FALSE)
hist(Mx2, main ="n=2", freq=FALSE) 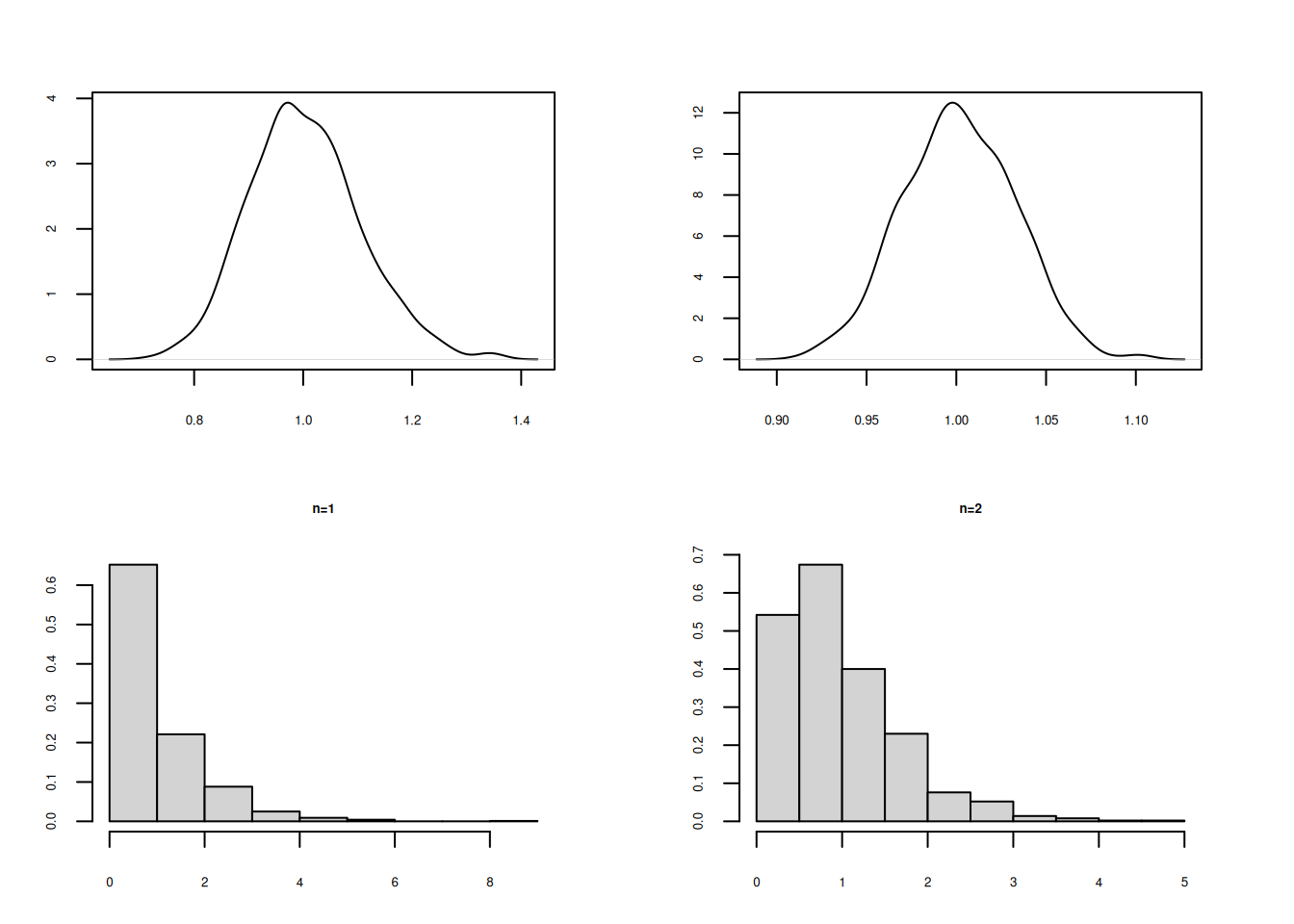
# hist(Mx20, main = "n=20",freq=FALSE)
hist(Mx30, main = "n=30",freq=FALSE)
hist(Mx50, main = "n=50",freq=FALSE)
hist(Mx100, main = "n=100", freq=FALSE)
hist(Mx1000, main = "n=1000", freq = FALSE) 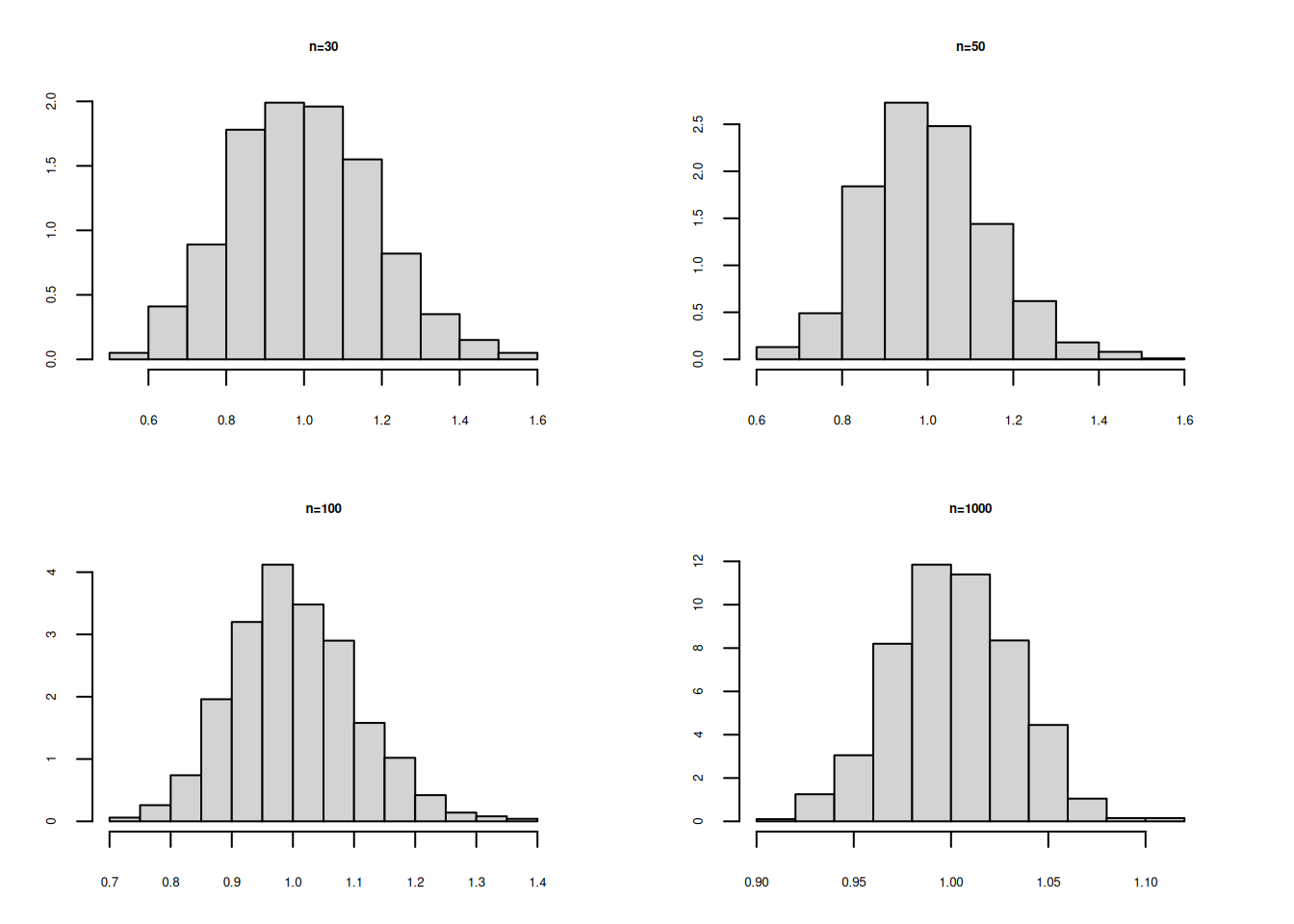
# histogramas de comparacion--------------------------
qqnorm(X1) ; qqline(X1, col="red")
qqnorm(Mx2) ; qqline(Mx2, col="red")
# qqnorm(Mx20) ; qqline(Mx20, col="red")
qqnorm(Mx30) ; qqline(Mx30, col="red")
qqnorm(Mx50) ; qqline(Mx50, col="red")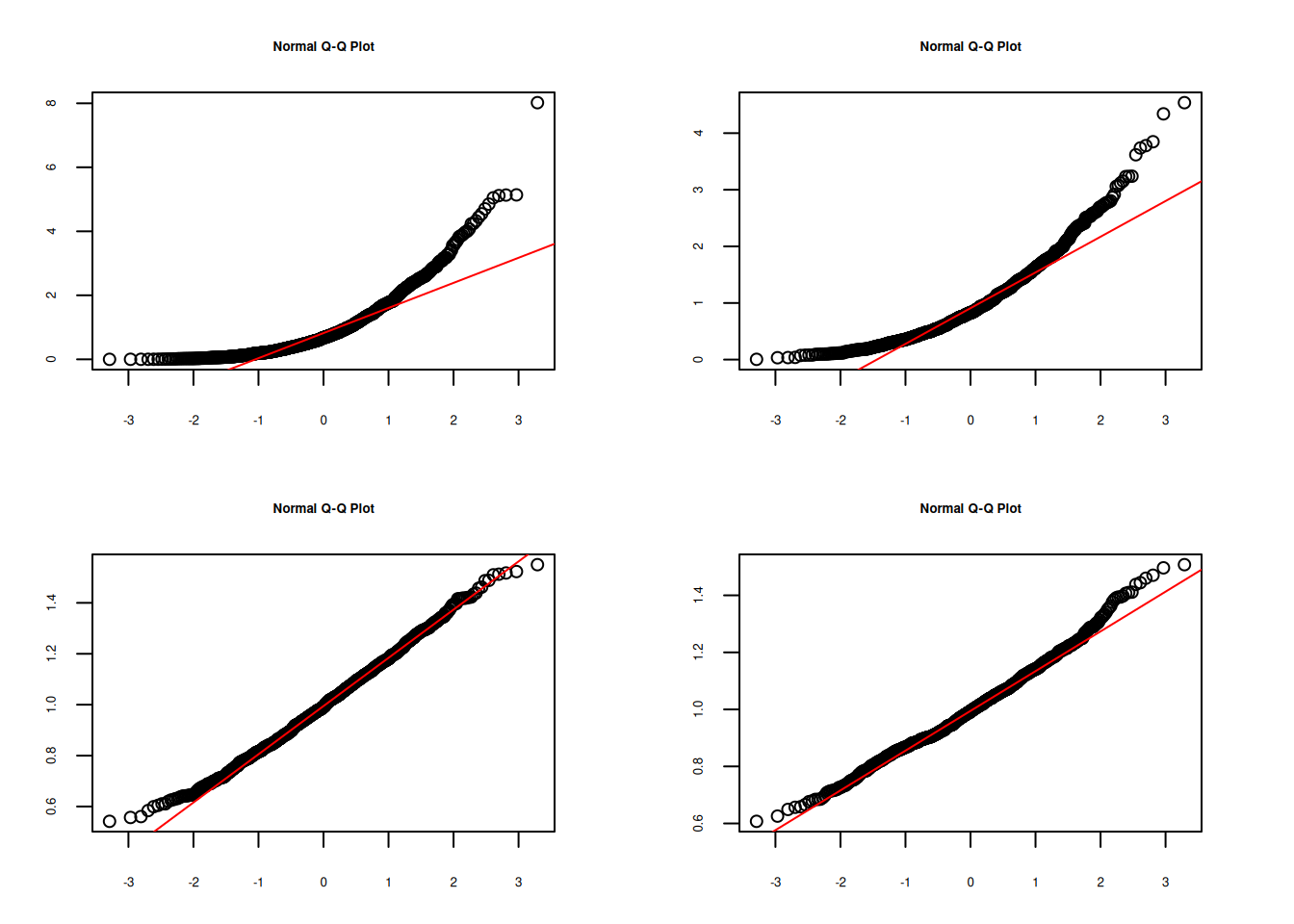
qqnorm(Mx100) ; qqline(Mx100, col="red")
qqnorm(Mx1000) ; qqline(Mx1000, col="red")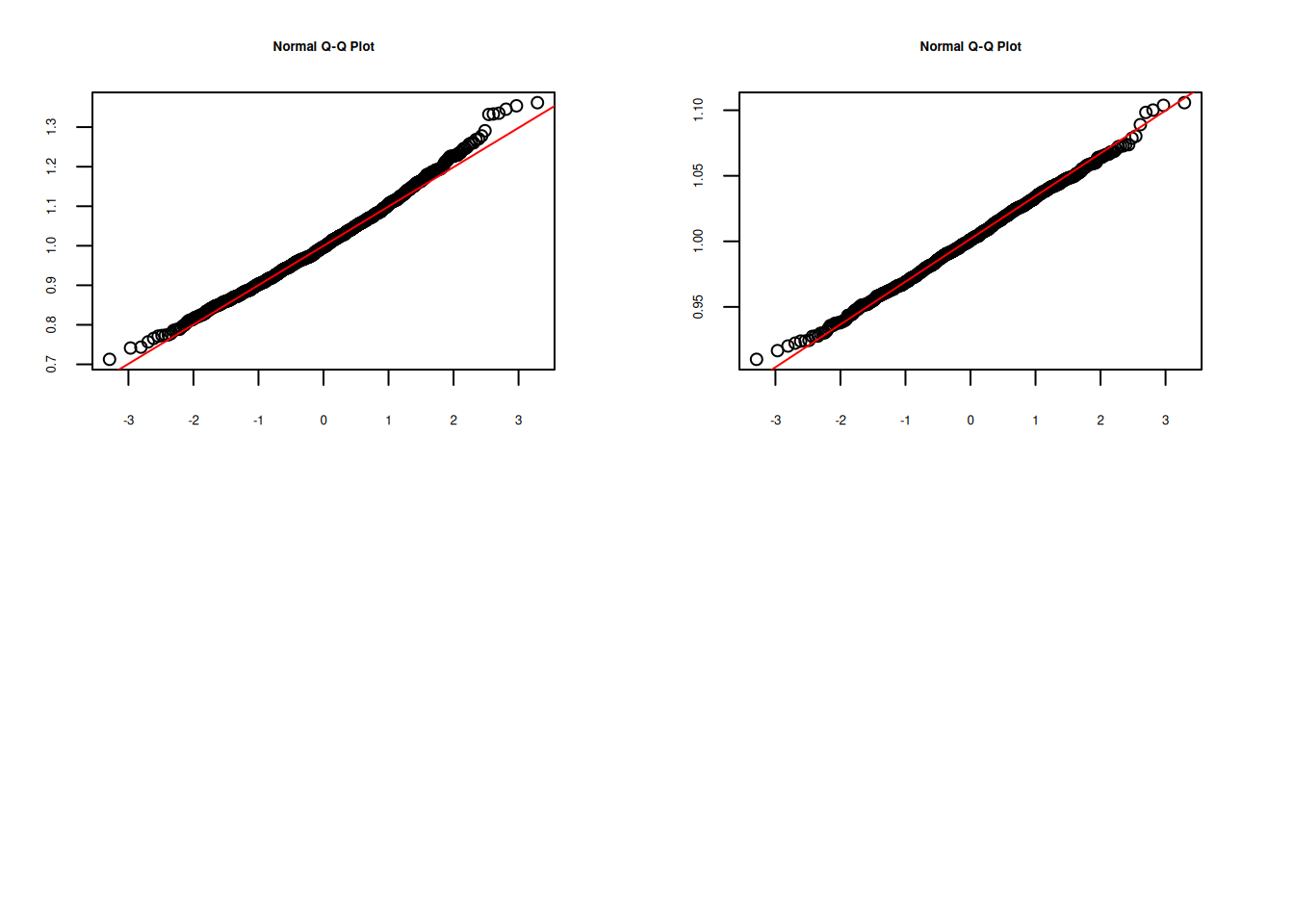
Se puede observar la convergencia de la distribución de la media muestral a una distribución normal al aumentarse el tamaño de la muestra
Distribuciones muestrales
A continuación se presentan las principales características de la media muestral \(\bar{x}\) y de la proporción muetral \(\widehat{p}\). En cada uno de los casos vamos a suponer el conocimiento de de una población pequeña.
Media muestral
Propiedades de la media muestral
Paso 1
Definir la población
Supongamos que una población esta conformada por los valores : \(\{1,2,3,4,5 \}\), donde \(N=5\)
Ahora que se desea calcular todas las medias que se puedan obtener de esta población para un tamaño de muestra \(n=2\). En otras palabras la población de medias para \(n=2\).
Inicialmente definimos dos funciones para calcular los parámetros poblacionales media y varianza:
\[\mu =\dfrac{1}{N} \sum_{i=1}^{N} x_{i}\]
\[\sigma^{2}= \dfrac{1}{N} \sum_{i=1}^{N} (x_{i}-\mu)^{2}\]
media=function(x){sum(x)/length(x)}
varianza=function(x){sum((x-media(x))^2)/(length(x))}Paso 2
Determinar la media y la varianza poblacional . La media y varianza poblacional de esta población estará dada por:
poblacion_x=c(1,2,3,4,5)
cat("media poblacional :",media(poblacion_x),"\n")media poblacional : 3 cat("varianza poblacional :",varianza(poblacion_x),"\n")varianza poblacional : 2 cat("\n")Paso 3
Se determinan todas las muestras que se pueden construir de la poblacion
Para determinar la media y la varianza de todas las medias muestrales para \(n=2\) que se pueden obtener de la población, suponemos que las muestras se escogen con repetición:
\((1,1), (1,2),(1,3),(1,4),(1,5),(2,1),(2,2),(2,3),.....,(5,5)\).
poblacion_n2=permutations(5,2,1:5, repeats=TRUE)
mx=apply(poblacion_n2, 1,mean)
data.frame(poblacion_n2,mx) X1 X2 mx
1 1 1 1.0
2 1 2 1.5
3 1 3 2.0
4 1 4 2.5
5 1 5 3.0
6 2 1 1.5
7 2 2 2.0
8 2 3 2.5
9 2 4 3.0
10 2 5 3.5
11 3 1 2.0
12 3 2 2.5
13 3 3 3.0
14 3 4 3.5
15 3 5 4.0
16 4 1 2.5
17 4 2 3.0
18 4 3 3.5
19 4 4 4.0
20 4 5 4.5
21 5 1 3.0
22 5 2 3.5
23 5 3 4.0
24 5 4 4.5
25 5 5 5.0 cat("media poblacional de la media muestral :", media(mx),"\n")media poblacional de la media muestral : 3 cat("varianza poblacional de la media muestral :",varianza(mx),"\n")varianza poblacional de la media muestral : 1 cat("\n") cat("Compara los resultados obtenidos con los respectivos valores de la población ")Compara los resultados obtenidos con los respectivos valores de la población plot(poblacion_n2, pch=19)
grid()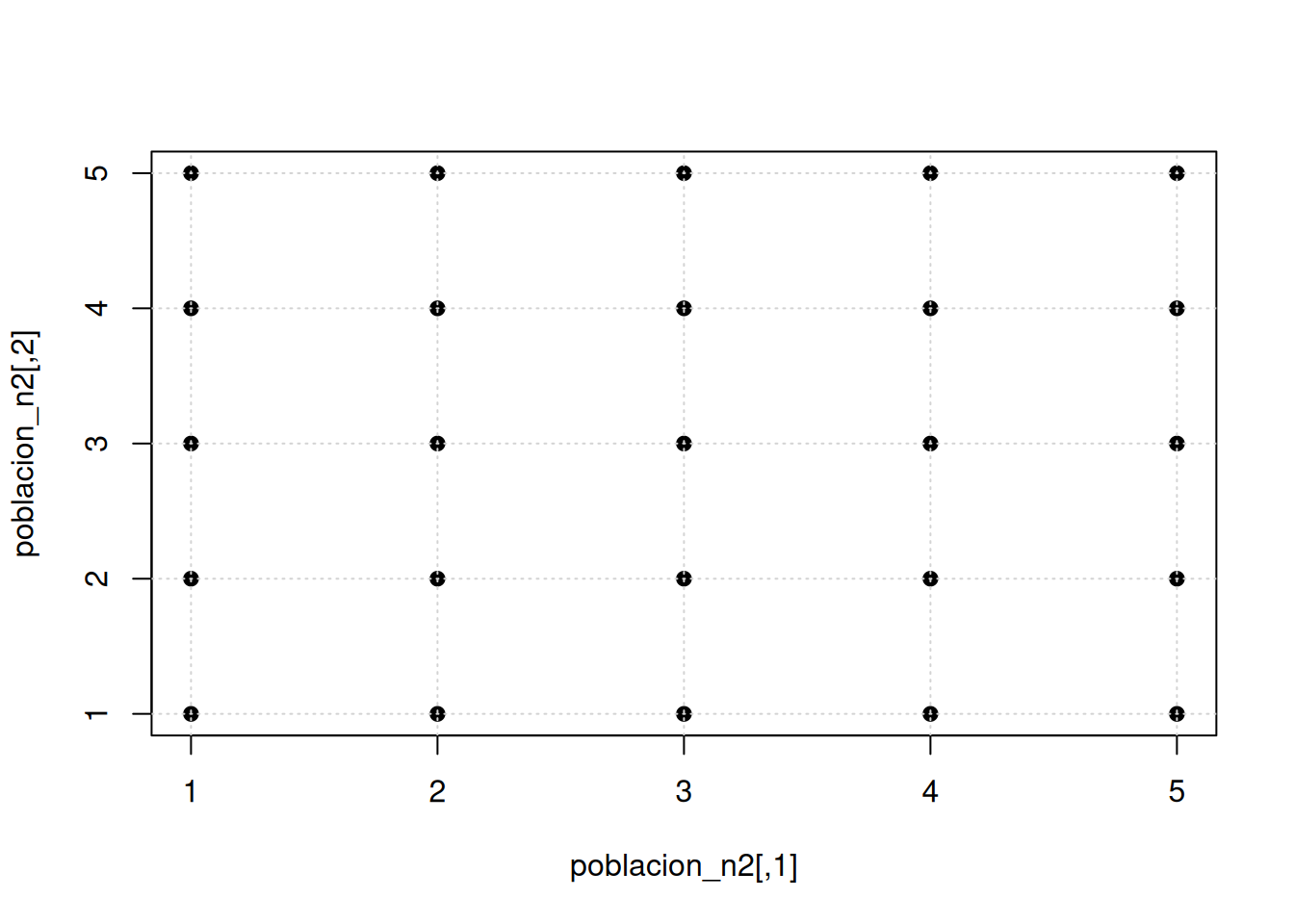
Paso 4
Determinar la población de medias de tamaño \(n=2\), cuando el proceso se realiza sin repetición
En este caso desaparen las muestras \((1,1),(2,2),(3,3),(4,4),(5,5)\) ademas de \((2,1)\), pues ya esta contenida en la muestra \((1,2\). En total quedaran 10 posibles muestras
X1 X2 mx
1 1 2 1.5
2 1 3 2.0
3 1 4 2.5
4 1 5 3.0
5 2 3 2.5
6 2 4 3.0
7 2 5 3.5
8 3 4 3.5
9 3 5 4.0
10 4 5 4.5media poblacionalde la media muestral : 3 varianza poblacional de la media muestral : 0.75Compara los resultados obtenidos con los respectivos valores de la población 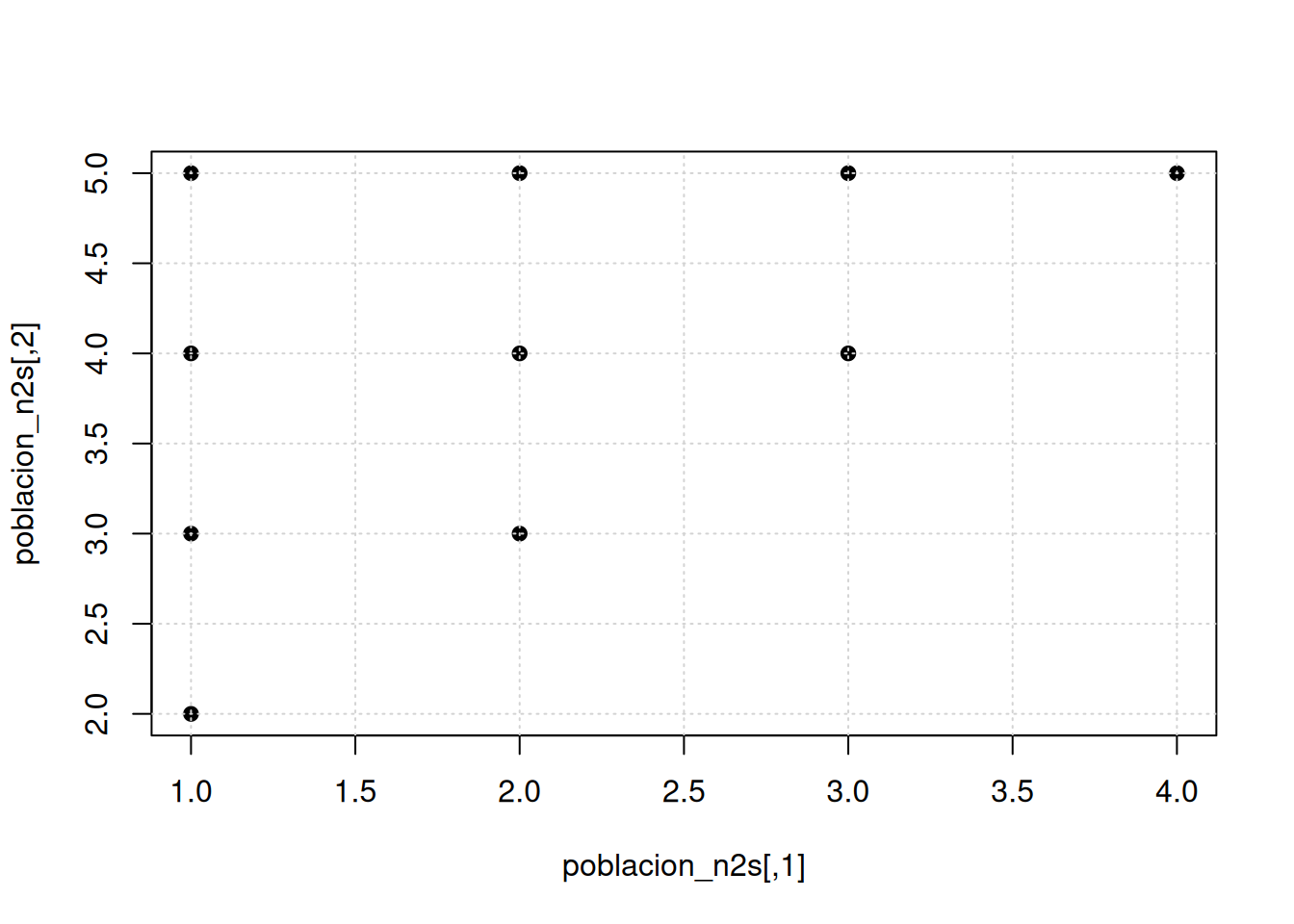
Conclusiones
\(E[\bar{X}] = E[X] = \mu\)
\(V[\bar{X}] = \dfrac{V[X]}{n}\)
Cuando \(\dfrac{n}{N}>0.05\), como el muestreo se realiza sin repeticion ( un cliente solo parece una vez en la muestra) , la probabilidad de seleecion en cada momento cambia a medida que se elige la muestra. Estos cambios hacen necesario realizar un ajuste en la varianza:
\[V[\bar{X}] = \dfrac{V[X]}{n} \dfrac{(N-n)}{(N-1)}\]
Proporción muestral
Otro parametro de intres es la proporcion muestral para lo cual tambien se define una población pequeña que facilite la compresión de sus propiedades.
Propiedades de la proporción muesrtal
Paso 1
Definir la población
Supongamos que una población esta conformada por \(\{\)si, no,si, no, no \(\}\)
Ahora que se desea calcular todas las medias que se puedan obtener de esta población para un tamaño de muestra \(n=2\).
En otras palabras la población de medias para \(n=2\).
library(gtools)
media=function(x){sum(x)/length(x)}
varianza=function(x){sum((x-media(x))^2)/(length(x))}Paso 2
Determinar la media y la varianza poblacioneales
La media y varianza poblacional de esta población estará dada por:
poblacion_x=c(1,0,1,0,0)
cat("media poblacional :",media(poblacion_x),"\n")media poblacional : 0.4 cat("varianza poblacional :",varianza(poblacion_x),"\n")varianza poblacional : 0.24 cat("\n")Paso 3
Se determinan todas las muestras que se pueden construir de la población
Para determinar la media y la varianza de todas las medias muestral s para \(n=2\) que se pueden obtener de la población, suponemos que las muestras se escogen con repetición:
\((si,si)\), \((si,no)\)……\((no,no)\)
x <- c("1-si", "2-no", "3-si","4-no","5-no")
muestra=permutations(n=5,r=2,v=x,repeats.allowed=T)
p=c(1,0.5,1,0.5,0.5,0.5,0,0.5,0,0,1,0.5,1,0.5,0.5,0.5,0,0.5,0,0,0.5,0,0.5,0,0)
data.frame(muestra,p) X1 X2 p
1 1-si 1-si 1.0
2 1-si 2-no 0.5
3 1-si 3-si 1.0
4 1-si 4-no 0.5
5 1-si 5-no 0.5
6 2-no 1-si 0.5
7 2-no 2-no 0.0
8 2-no 3-si 0.5
9 2-no 4-no 0.0
10 2-no 5-no 0.0
11 3-si 1-si 1.0
12 3-si 2-no 0.5
13 3-si 3-si 1.0
14 3-si 4-no 0.5
15 3-si 5-no 0.5
16 4-no 1-si 0.5
17 4-no 2-no 0.0
18 4-no 3-si 0.5
19 4-no 4-no 0.0
20 4-no 5-no 0.0
21 5-no 1-si 0.5
22 5-no 2-no 0.0
23 5-no 3-si 0.5
24 5-no 4-no 0.0
25 5-no 5-no 0.0cat("media de la proporcion muestral : ",media(p), "\n")media de la proporcion muestral : 0.4 cat("varianza de la proporcion muestral : ", varianza(p))varianza de la proporcion muestral : 0.12Paso 4
Determinar la población de medias de tamaño \(n=2\), cuando el proceso se realiza sin repetición
En este caso desaparen las muestras \((1,1),(2,2),(3,3),(4,4),(5,5)\) ademas de \((2,1)\), pues ya esta contenida en la muestra \((1,2\). En total quedaran 10 posibles muestras
X1 X2 mp
1 1-si 2-no 0.5
2 1-si 3-si 1.0
3 1-si 4-no 0.5
4 1-si 5-no 0.5
5 2-no 3-si 0.5
6 2-no 4-no 0.0
7 2-no 5-no 0.0
8 3-si 4-no 0.5
9 3-si 5-no 0.5
10 4-no 5-no 0.0media poblacional de la media muestral : 0.4 varianza poblacional de la media muestral : 0.09 Compara los resultados obtenidos con los respectivos valores de la poblacion Conclusiones
\(E[\widehat{p}] = p\)
\(V[\widehat{p}] = \dfrac{pq}{n}\)
Si \(\dfrac{n}{N}>0.05\), se hacen necesario realizar un ajuste en la varianza:
\[V[\widehat{p}] = \dfrac{pq}{n} \dfrac{(N-n)}{(N-1)}\]
Muestreo
Muestreo aleatorio simple
Para seleccionar una muestra de una variables, supongamos que se distinguen por un Id del 1 al 1000, utilizamos la funcion sample para seleccionar la muestra:
x<-seq(1,1000,1)
sample(x, 20) [1] 978 386 738 442 87 817 654 510 860 448 412 247 451 432 352 328 812 99 853
[20] 900En este caso se ha seleccionado una muestra de tamaño \(n=10\) de una población de \(N=1000\) unidades. Dato que la población es muy grande es poco probable que un valor salga repetido, por lo que se conoce como muestreo sin repetición.
Es posible realizar un muestreo con repetición en el caso de que la población sea demasiado pequeña (este tipo de muestreos se llaman bootstrap o remuestreo) :
x<-1:10
sample(x, 20, replace = TRUE) [1] 7 10 1 1 6 9 2 7 7 2 4 8 7 3 4 8 10 9 1 1Muestreo sistemático
N=2000
a=100
ids=S.SY(N, a)
ids [,1]
[1,] 84
[2,] 184
[3,] 284
[4,] 384
[5,] 484
[6,] 584
[7,] 684
[8,] 784
[9,] 884
[10,] 984
[11,] 1084
[12,] 1184
[13,] 1284
[14,] 1384
[15,] 1484
[16,] 1584
[17,] 1684
[18,] 1784
[19,] 1884
[20,] 1984Ejemplo muestreo aleatorio simple
# se importa base de datos
library(readr)
base_muestreo <- read_delim("data/base_muestreo.csv",
delim = ";", escape_double = FALSE, col_types = cols(ID = col_integer()),
trim_ws = TRUE)
head(base_muestreo) # primeras 6 filas de la base# A tibble: 6 × 1
`ID,CAR,NF`
<chr>
1 1,CIV,3
2 2,BIO,2.7
3 3,ELE,3.5
4 4,ELE,4.3
5 5,ELE,4.2
6 6,ELE,4 dim(base_muestreo) # dimension de la base[1] 180 1Para seleccionar una muestra aleatoria mediante el muestreo aleatorio simple de la base utilizamos la función sample
# se extre la muestra
muestra1=base_muestreo[sample(1:nrow(base_muestreo),50,replace=F),] Ejemplo muestreo aleatorio sistemático
Ahora si se requiere un muestreo sistemático
N=180
n=10
a=N/n
ids=S.SY(N, a)
ids [,1]
[1,] 17
[2,] 35
[3,] 53
[4,] 71
[5,] 89
[6,] 107
[7,] 125
[8,] 143
[9,] 161
[10,] 179base2=base_muestreo[ids,]
base2# A tibble: 10 × 1
`ID,CAR,NF`
<chr>
1 17,IND,3.3
2 35,IND,3.5
3 53,CIV,4.7
4 71,IND,3.2
5 89,IND,2.4
6 107,IND,3.1
7 125,IND,4.5
8 143,CIV,2.3
9 161,CIV,2
10 179,CIV,1.7Para los casos de los muestreos estratificado y muestreo por conglomerados se utiliza el muestreo aleatorio simple como base.
PaqueteDEG
- Instalación del paquete.
El paquete paqueteDEG en construcción permitirá realizar algunos cálculos del tamaño de la muestra y tutoriales. Para su instalación corremos el siguiente código
# install.packages("devtools") # solo si no esta instalado
devtools::install_github("dgonxalex80/paqueteDEG")- Calculo del tamaño de la muestra para la estimación de una media poblacional
Ejemplo:
Determinar el tamaño de la muestra para estimar la media de una variable, en una población de tamaño \(N = 2000\) con varianza conocida igual a \(\sigma^{2}=3025\), con una confianza del 95% y un error de muestreo de 5 unidades
Solución:
Información del problema :
- \(\sigma^{2}=3025\) –> \(\sigma = 55\)
- \(N = 2000\)
- Confianza del 95% : Percentil 97.5 = \(z_{_{\alpha/2}} = 1.96\)
- Error de muestreo : \(e = 5\)
\[n = \dfrac{ z_{_{\alpha/2}} \times \sigma^{2} }{e^{2}} =\dfrac{1.96^{2} \times 3025 }{5^{2}} =464.83 \sim 465\]
Ahora con una base de datos que contiene la carrera y la nota final del curso de matemáticas fundamental.
head(base_muestreo)# A tibble: 6 × 1
`ID,CAR,NF`
<chr>
1 1,CIV,3
2 2,BIO,2.7
3 3,ELE,3.5
4 4,ELE,4.3
5 5,ELE,4.2
6 6,ELE,4 cat("dimensión de la base : ", dim(base_muestreo), "\n")dimensión de la base : 180 1 cat("media poblacional ", mean(base_muestreo$NF), "\n")media poblacional NA t=table(base_muestreo$CAR)
cat("proporción poblacional : ", t[2]/sum(t))proporción poblacional : NACon 180 mregistros y tres columnas o variables :
- ID : identificación del estudiante
- CAR : programa en el que se encuentra matriculado
- NF : nota final de matemáticas fundamentales
Como seleccionar una muestra aleatoria de 20 estudiantes:
idm=sample(1:80, 30)
muestra =base_muestreo[idm,]
muestra# A tibble: 30 × 1
`ID,CAR,NF`
<chr>
1 61,MAT,4.4
2 34,ELE,1.1
3 78,IND,3.7
4 80,BIO,3
5 56,MAT,3.5
6 19,IND,2.4
7 65,IND,4.1
8 12,SIS,3.4
9 22,SIS,4.5
10 20,IND,4.6
# ℹ 20 more rows