
Recursos
Antes de empezar con el tema reflexionemos sobre los siguientes interrogantes:
¿Qué es la probabilidad?
# La probabilidad es una medida matemática que cuantifica la posibilidad de ocurrencia de un evento dentro de un espacio de resultados posibles. Se expresa como un número entre 0 y 1, donde 0 representa imposibilidad y 1 certeza.
# Ross, S. (2014). Introduction to Probability Models (11th ed.). Academic Press.¿Cuál es su uso…..?
# La probabilidad se utiliza para modelar fenómenos aleatorios, tomar decisiones en condiciones de incertidumbre, evaluar riesgos, predecir comportamientos y apoyar en la estadística inferencial. Se aplica en áreas como economía, biología, ingeniería y ciencias sociales.
# Feller, W. (2008). An Introduction to Probability Theory and Its Applications (Vol. 1). Wiley.¿Como se mide……?
# La probabilidad se mide dividiendo el número de casos favorables entre el número total de casos posibles (cuando todos los resultados son igualmente probables). En contextos más generales, se mide a través de funciones de probabilidad y distribuciones.
# Grimmett, G., & Stirzaker, D. (2001). Probability and Random Processes (3rd ed.). Oxford University Press.¿Que tipos de probabilidad existen?
# Clásica: basada en el conteo de casos favorables y posibles.
# Frecuentista: definida como el límite de la frecuencia relativa de un evento cuando el número de repeticiones tiende al infinito.
# Subjetiva: depende de la creencia o juicio personal respecto a la ocurrencia de un evento.
# Kolmogorov, A. (1956). Foundations of the Theory of Probability. Chelsea Publishing.¿Qué propiedades posee….?
# No negatividad: P(A) ≥ 0.
# Normalización: P(S) = 1, siendo S el espacio muestral.
# Aditividad: Si A y B son eventos mutuamente excluyentes, entonces P(A ∪ B) = P(A) + P(B).
# Casella, G., & Berger, R. (2002). Statistical Inference (2nd ed.). Duxbury.¿Qué significado tienen las palabras…
Azar - Aleatorio
# Azar: acontecimiento sin causa aparente o previsible.
# Aleatorio: fenómeno que no es determinístico. Es posible se modelado
# Ross, S. (2014). Introduction to Probability Models.Determinístico - No deterministico
# Determinístico: el resultado está completamente definido por las condiciones iniciales.
# No determinístico: el resultado no puede predecirse con certeza, depende del azar
# Ross, S. (2014). Introduction to Probability Models.Incertidumbre - Probable - Improbable
# Incertidumbre: ausencia de certeza sobre un resultado.
# Probable: evento con posibilidad de ocurrencia.
# Improbable: evento con muy baja posibilidad de ocurrencia.
# Kahneman, D., & Tversky, A. (1979). Prospect Theory: An Analysis of Decision under Risk. Econometrica, 47(2), 263–291.Cierto - Incierto - Imposible
# Cierto: evento que ocurre con probabilidad 1.
# Incierto: evento con probabilidad entre 0 y 1.
# Imposible: evento que ocurre con probabilidad 0.
# Kolmogorov, A. (1956). Foundations of the Theory of Probability.
 Fuente : diario El Pais
Fuente : diario El Pais
Aunque a menudo leemos en los diarios el termino PROBABILIDAD, muchos relacionamos el concepto con los dados, pues forma parte de su origen y de su desarrollo inicial a través de preguntas y situaciones imaginarias y de alguna forma modelables desde la matemáticas. Pero este concepto va mucho mas alla como lo veremos en esta unidad.
La probabilidad es un concepto que se empieza a trabajar en 1654 cuando, caballero de Mered solicita a B. Pascal le ayude a resolver un problema relacionado con juegos de mesa. En particular este caballero manifestaba que las Matemáticas presentaban un vacio, pues sus cálculos no coincidían con lo que pasaba en la realidad y como consecuencia de ellos perdía dinero en las apuestas que se presentaban en el juego.
Encomendado Pascal de esta tarea empieza a compartir su trabajo con Fermat, matemático y de la correspondencia de estos dos brillantes matemáticos nace los principios y fundamentos de lo que hoy conocemos como probabilidad.

Con el fin de motivar la construcción de los conceptos principales del tema se plantean las siguientes situaciones :
Problema
El siguiente problema fué planteado por el Caballero de Meré a Pascal quien lo consultó con Fermata y conforma una serie de situaciones que dan origen a soluciones que conforman los inicios del estudio de la Probabilidad (1654).
Los dados, tal y como los conocemos hoy en día, se hicieron muy populares en la edad media. En esta época un caballero llamado Chevalier de Mere propuso el siguiente problema:
Qué es más probable :
Sacar al menos un seis en cuatro tiradas con un solo dado o
Sacar al menos un doble seis en 24 tiradas con dos dados?
El caballero afirmaba que este problema generaba una solución matemática que difería de la observación empírica
Este problema se retoma mas adelante
Iniciaremos con algunos conceptos básicos que nos permiten la contribución de sus fundamentos.
El problema de los dados del caballero de Meré: soluciones publicadas en el siglo XVII

Conceptos básicos
Experimento aleatorio
Acción que puede ser replicada bajo las mismas condiciones y cuyo resultado no se conoce por anticipado.
\(E_{1}\): Lanzar una moneda dos veces y observar los resultados obtenidos en sus caras superiores
\(E_{2}\): Lanzar dos dados y observar la suma de los resultados superiores
\(E_{3}\): Realizar un examen de estadística y observar el resultado obtenido
\(E_{4}\): En una salida de campo, observo si se cumple o no, totalmente el objetivo planteado
\(E_{5}\): Observo el número total de ensayos de laboratorio exitosos en 20 intentos realizados.
Espacio muestral
Conjunto de todos los posibles valores que puede tomar el experimento aleatorio. Este conjunto se nombra conuna letra mayuscula \(S\) o tambien con \(\Omega\)
- \(S_{1}\)= \(\{ (cc), (cs), (sc), (ss) \}\)
- \(\begin{equation*} S_{2}=\left\{ \begin{array}{cccccc} &(1,1),(1,2),(1,3),(1,4),(1,5),(1,6)&\\ &(2,1),(2,2),(2,3),(2,4),(2,5),(2,6)&\\ &(3,1),(3,2),(3,3),(3,4),(3,5),(3,6)&\\ &(4,1),(4,2),(4,3),(4,4),(4,5),(4,6)&\\ &(5,1),(5,2),(5,3),(5,4),(5,5),(5,6)&\\ &(6,1),(6,2),(6,3),(6,4),(6,5),(6,6)& \end{array} \right\} \end{equation*}\)

- \(S_{3}\)= \(\{ x \in \mathbb{R} | 0 \leq x \leq 5 \}\)
- \(S_{4}\)= \(\{ x \in \mathbb{N}| 0 \leq x \leq 1 \}\)
- \(S_{5}\)= \(\{ x \in \mathbb{N}| 0 \leq x \leq 20 \}\)
Evento aleatorio
Subconjunto del espacio muestral que es de nuestro interés. Como todo conjunto se nombra con una letra mayúscula por lo general las primeras letras del alfabeto
| \(A_{1}\) | Obtener solo caras | \(A_{1}=\{ (c,c)\}\) |
| \(A_{2}\) | Sacar un resultados es inferior a 4 | \(A_{2}=\{(1,1),(1,2)(2,1)\}\) |
| \(A_{3}\) | Ganar el examen | \(A_{3}=\{ x \in \mathbb{R} | 3.0 \leq x \leq 5.0 \}\) |
| \(A_{4}\) | Cumplir el objetivo de la salida | \(A_{4} =\{ 1 \}\) |
| \(A_{5}\) | Obtener más de 5 ensayos éxitos | \(A_{5}\)= \(\{ x \in \mathbb{N}| 6 \leq x \leq 20 \}\) |
Resumiendo:
| Experimento aleatorio | Espacio muestral | Evento aleatorio |
|---|---|---|
| Lanzar una moneda dos veces y observar los resultados obtenidos en sus caras superiores | \(S_{1}\)= \(\{ (cc), (cs), (sc), (ss) \}\) | Obtiener solo caras |
| Lanzar dos dados y observar la suma de los resultados superiores | \(S_{2}\)= \(\{(1,1),(1,2), \dots, (6,6) \}\) | Sacar un resultados es inferior a 6 |
| Realizar un examen de estadística y observar el resultado obtenido | \(S_{3}\)= \(\{ x \in \mathbb{R} | 0 \leq x \leq 5 \}\) | Ganar el examen |
| En una salida de campo, observo si se cumple o no, totalmente el objetivo planteado | \(S_{4}\)= \(\{ x \in \mathbb{N}| 0 \leq x \leq 1 \}\) | Cumplir el objetivo de la salida |
| Observo el número total de ensayos de laboratorio exitosos en 20 intentos realizados | \(S_{5}\)= \(\{ x \in \mathbb{N}| 0 \leq x \leq 20 \}\) | Obtener más de 5 ensayos éxitos |
Enfoques de probabilidad
Enfoque clásico
Es el enfoque más antiguo de probabilidad y que está basado en el supuesto de eventos individuales igualmente probables. La probabilidad bajo ese enfoque para el evento \(A\) se calcula como la fracción entre el número de elementos del conjunto \(A\), \(n(A)\) y el número de elementos del espacio muestral \(n(S)\):
\[P(A)=\dfrac{n(A)}{n(S)}\]
En el caso del evento \(A_{1}=\{(c,c)\}\), su probabilidad se obtiene como:
\(P(A_{1}=\dfrac{n(A_{1})}{n(S_{1})}=\dfrac{1}{4}=0.25\)
Para \(A_{2}\), la suma de los resultados es inferior a 6, se obtiene de la siguiente forma
\(P(A_{2})=\dfrac{n(A_{2})}{n(S_{2})}=\dfrac{9}{36}=0.25\)
En la gran mayoria de casos no se cumplen los supuestos anteriores, pues se tienen eventos que no son igualmente probables, lo cual impide que podamos utilizar el enfoque frecuentista.
Ahora suponemos que lo ocurrió en el pasado segirá pasando y asi estudiando la información recogida podemos predecir la posibilidad de ocurrencia de un evento futuro
Enfoque Frecuentista
Este enfoque basa su cálculo en la frecuencia con que ocurre un evento en un tamaño de muestra determinado \(n\).
\[\lim_{n \to{+}\infty} P(A)=\Bigg[ \dfrac{\text{número de veces que ocurre A}}{n} \Bigg]\]

Si observamos el cobro de un penalti en un partido de fútbol, el cobrador tiene un gran número de posibilidades (lugares) para colocar el balón que podemos simplificar en 6 : parte baja derecha, parte alta derecha, parte baja al centro, parte alta central, parte baja izquierda y parte alta izquierda. Por su parte el arquero piensa también es estos lograres para evitar que el disparo termine en gol. Hoy en dia ambos jugadores estudian las frecuencias para determinar cual lugar ofrece mayores probabilidades de obtener éxito desde su rol.
Para calcular la probabilidad de que un jugador ejecute y convierta gol, debemos utilizar el enfoque frecuentista, contando para ello información pasada y realizando una división entre el numero de aciertos sobre el numero total de cobros.
Otro ejemplo puede estar relacionado con la probabilidad de muerte por Covid en Colombia. Es de aclarar que esta probabilidad no se mantiene constante a través del tiempo pues los efectos causados por la vacunación y su evolución hacen que esta probabilidad cambie. Por fines prácticos tomaremos la base total de colombianos infectados desde marzo del 2019 como denominador y como numerador el numero total de muertos
Colombia=readRDS("data/Colombia22.RDS")
tabla=summarytools::freq(Colombia22$ubicacion, cumul = FALSE)
tablaCon base en esta tabla podríamos pensar que la probabilidad de que
una persona muera a causa del Covid-19 es del 0.0289. Valor
que se obtiene al dividir el número de personas fallecidas y el número
total de personas que se han contraído covid. Claro bajo el supuesto de
que todos las personas tenemos la misma probabilidad de fallecer. Hecho
que se discutirá mas adelante.
Enfoque subjetivo
En este caso la probabilidad es valorada y asignada por un EXPERTO, como un médico, un ingeniero, un abogado, un economista, un biólogo, un estadístico ……
Axiomas de probabilidad
- \(A_{1}\) : Sea \(S\) un espacio muestral asociado a un experimento. Entonces:
\[P(S)=1\]
- \(A_{2}\) : Para cualquier evento \(A\), se cumple que:
\[0 \leq P(A) \leq 1\]
- \(A_{3}\) : Si \(A\) y \(B\) son dos eventos mutuamente excluyentes, entonces: \[P(A \cup B) = P(A) + P(B)\] En general
\[P(A \cup B) = P(A)+ P(B) - P(A \cap B)\]
\(A_{4}\) : Para cualquier evento \(A\), \(P(A')=1-P(A)\)
\(A_{5}\) : La probabilidad que no ocurra nada :
\[P(\phi) = 0\]
Tipos de probabilidad
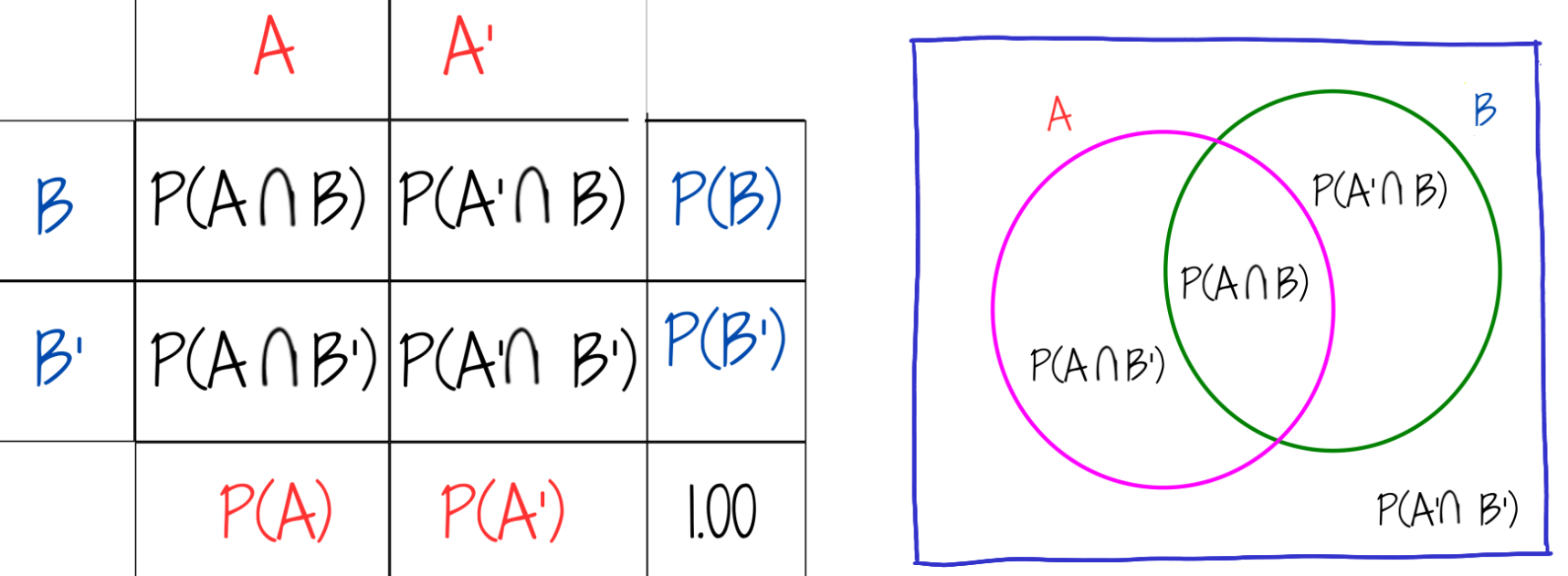
Probabilidad simple o marginal
\(P(A)\) : probabilidad de que ocurra A
\(P(A')\) : probabilidad de que NO ocurra A
\(P(B)\) : probabilidad de que ocurra B
\(P(B')\) : probabilidad de que NO ocurra B
Probabilidad conjunta
\(P(A \cap B)\) : probabilidad de que ocurra A y B
\(P(A' \cap B)\) : probabilidad de que NO ocurra A y ocurra B
\(P(A \cap B')\) : probabilidad de que ocurra A y NO ocurra B
\(P(A' \cap B')\) : probabilidad de que NO ocurra A ni B
En un estudio se observa la relación entre plantas que presentan floración (\(A\)) y aquellas que están en un hábitat húmedo (\(B\)).
\(A\) : La planta florece
\(B\) : La planta está en hábitat húmedo
library(knitr)
library(kableExtra)
biologia <- matrix(
c(0.35, 0.25, 0.60,
0.15, 0.25, 0.40,
0.50, 0.50, 1.00),
nrow = 3, byrow = TRUE
)
colnames(biologia) <- c("A", "A'", "Total")
rownames(biologia) <- c("B", "B'", "Total")
kable(biologia, digits = 2,caption = " ") %>%
kable_styling(full_width = FALSE, bootstrap_options = c("striped", "condensed"), position = "center") %>%
column_spec(1, width = "6em") %>% # Ajusta ancho de la primera columna
column_spec(2, width = "6em") %>% # Ajusta ancho de la columna A
column_spec(3, width = "6em") %>% # Ajusta ancho de la columna A'
column_spec(4, width = "7em") # Ajusta ancho de la columna Total| A | A’ | Total | |
|---|---|---|---|
| B | 0.35 | 0.25 | 0.6 |
| B’ | 0.15 | 0.25 | 0.4 |
| Total | 0.50 | 0.50 | 1.0 |
En una universidad se estudia la relación entre estudiantes que aprueban un curso de Programación Avanzada (A) y aquellos que entregan a tiempo el proyecto final (B).
- \(A\): El estudiante aprueba el
curso
- \(B\): El estudiante entrega el proyecto a tiempo
library(knitr)
library(dplyr)
sistemas <- matrix(
c(0.40, 0.15, 0.55,
0.20, 0.25, 0.45,
0.60, 0.40, 1.00),
nrow = 3, byrow = TRUE
)
colnames(sistemas) <- c("A", "A'", "Total")
rownames(sistemas) <- c("B", "B'", "Total")
kable(sistemas, digits = 2,caption = " ") %>%
kable_styling(full_width = FALSE, bootstrap_options = c("striped", "condensed"), position = "center") %>%
column_spec(1, width = "6em") %>% # Ajusta ancho de la primera columna
column_spec(2, width = "6em") %>% # Ajusta ancho de la columna A
column_spec(3, width = "6em") %>% # Ajusta ancho de la columna A'
column_spec(4, width = "7em") # Ajusta ancho de la columna Total| A | A’ | Total | |
|---|---|---|---|
| B | 0.4 | 0.15 | 0.55 |
| B’ | 0.2 | 0.25 | 0.45 |
| Total | 0.6 | 0.40 | 1.00 |
Para cada uno de los ejemplos anteriores escriba los eventos marginales y los eventos conjuntos con su respectivos valores de probabilidad.